
 中国指挥与控制学会会刊
中国指挥与控制学会会刊 近年来,大语言模型技术的出现对人工智能领域产生了重大影响[1-2]。大语言模型经过大量文本数据的预训练,通过实现复杂的语言理解和生成功能,催化了人工智能技术的重大进步,为各领域广泛的应用打开了大门。在军事领域,大模型为军事智能化提供了创新型的解决方案和更广阔的发展空间,其包含的丰富知识库同时可以为军事需求生成提供支撑。在现代军事领域,作战指挥对应的作战仿真具有重要作用,基于多智能体的建模与仿真技术能够详细描述军事系统结构框架、分析作战要素和能力,在战场上帮助完成任务并做出决策,主要体现在信息收集与情报分析、武器系统开发、军事训练与作战仿真、医疗诊断与治疗、认知渗透攻击与网络安全防御、任务规划与供应链管理等方向[3]。
然而,在特定应用场景中单一运用大模型仍存在时效性弱、适应力差、专业性欠缺等问题。为解决单一大模型的局限性问题,已有研究提出大模型驱动多智能体协作的架构,通过多个自主的智能体的认知协同作用来完成复杂的任务、目标或问题[4-5]。大模型驱动的多智能体框架将特定应用场景中的目标分解为更小的可管理任务,并将任务分配给具有不同推理能力的智能体,提升大模型利用数据集、专业领域工具或其他基础模型等环境资源的能力。
针对不同的领域需求特点,结构化方法能够对多智能体系统进行评估,为多智能体系统在不同领域的性能分析提供标准。基于多智能体系统的评估领域提供了基于通信方法、任务分解、资源共享和冲突解决等评估策略的研究结果[6-8]。但是,早期的多智能体系统评估法相对简单,不适用于评估复杂的大模型驱动下的多智能体系统。此外,虽然自主性和一致性标准在人工智能系统的架构设计中具有基础性作用[9],且已有研究证明自主性和一致性对基于大模型的多智能体系统的运行结果产生较大影响,但是,目前国内研究对基于大模型的多智能体的评估策略尚未结合自主性和一致性指标来分析系统性能。因此,已有的系统评估法存在一定限制,不适用于大模型驱动的多智能体系统的评估研究。
本文基于自主性和一致性特征对系统进行评估分析,并对各核心功能的系统性能进行评估,快速高效地生成评估结果,有助于对系统架构动态进行细致的分析和评估。
1 大模型驱动的多智能体架构
在人工智能领域,智能体是指有能力感知周围的环境,做出决策,然后采取行动的实体,具有巨大的智能活动潜力,被认为是实现人工通用智能的关键技术。大模型在知识获取、指令理解、泛化、规划和推理方面具备强大的能力,并且能够与用户进行有效的自然语言交互,因此成为驱动多智能体协同合作以解决复杂任务的有力工具。
1.1 架构组成
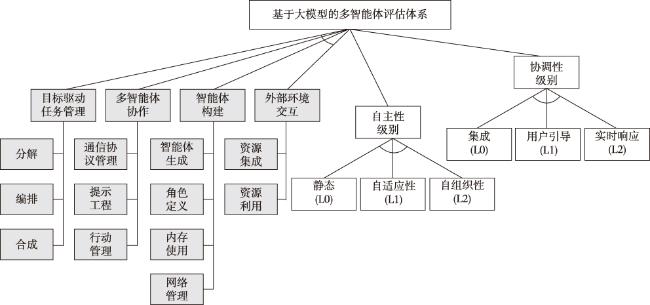
为了全面描述大模型驱动的多智能体架构特征,本文参考Kruchten提出的软件“4+1”视图架构模型,建立通用的大模型驱动的多智能体架构模型。模型在Kruchten提出的4个关键工作模式,即目标驱动的任务管理、智能体构建、多智能体协作和外部环境交互的基础上,提取出12个大模型驱动的多智能体系统的核心功能特征,对每个提取特征进行自主性和一致性评估。相较于直接对整个系统进行自主性和一致性评估的方法,本文的方法能够提供一种综合的多视角分析,揭示对系统内行为和组成等复杂运行模式的评估结果。
本文采用的大模型驱动的多智能体系统的主要架构如图1 所示。该框架可根据不同的应用领域进行功能定制。多智能体在架构中主要发挥如下3个作用:首先,根据用户输入需求提取目标任务,对目标任务进行分解、编排和合成,生成处理结果;其次,驱动大模型进行多智能体协作和智能体构建管理等;最后,与外部环境进行交互,获取外部工具、数据集和基础模型等外部资源。可知,大模型能够提供自然语言理解、分布式决策、群体智能交互模拟和关键词生成等辅助功能,具备根据多智能体的提示和管理指令,驱动智能体生成和角色定义、智能体与外部资源交互、智能体提取用户需求内容并编排合成的能力。
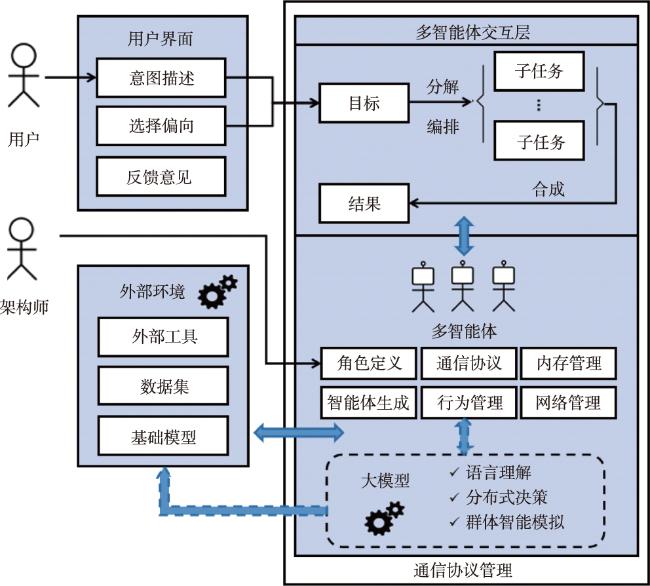
首先,目标驱动的任务管理模式描述系统根据用户的功能需求实现的逻辑结构。目标驱动的任务管理采用交互式和多视角的策略来完成用户提示的目标或复杂任务。在面对指定目标时,系统会根据功能点将复杂任务分解为更小、更易于管理的任务,并将子任务分配给各个具备特定能力的智能体,该策略能够有效关联子任务,并综合模式结果,提升最终结果的全面性和连贯性。
其次,智能体构建模式描述系统根据功能模块开发需求实现的开发架构。作为基础组件的构建系统,每个智能体都具有独特的功能,包括明确定义的角色、个人记忆、与其他智能体之间的通信以及对任务所需的外界资源的访问,包括数据、工具或基础模型。
再次,多智能体协作模式描述系统根据模块管理需求实现的进程架构。多智能体协作通过交互层建立大模型驱动的多智能体网络。在执行分配的任务时,多个智能体通过消息交换相互协作,包括指定任务、询问信息或评估任务结果。
最后,外部环境交互模式描述系统根据物理配置需求实现的物理结构。外部环境交互获取专家工具、数据、基础模型或其他应用程序等外部资源,提升系统收集、适应和响应复杂环境信息的能力,有效执行复杂任务。
1.2 架构工作流程
大模型驱动的多智能体架构每个关键模式的工作流程如图2 所示,系统架构共包括12个核心功能,大模型的驱动作用主要体现在分解、编排、合成、角色定义、资源集成和资源利用等特征功能中。框架的运行流程如下:首先,用户指定领域目标和功能定义,提供数据、工具和模型等外部资源;其次,多个专业智能体协同处理外部资源信息,通过大模型驱动进行目标分析和子任务分解,并与用户进行交互;再次,系统形成任务模块,并通过与外部环境资源交互进行深入求解。最后,多智能体生成处理结果并反馈给用户。
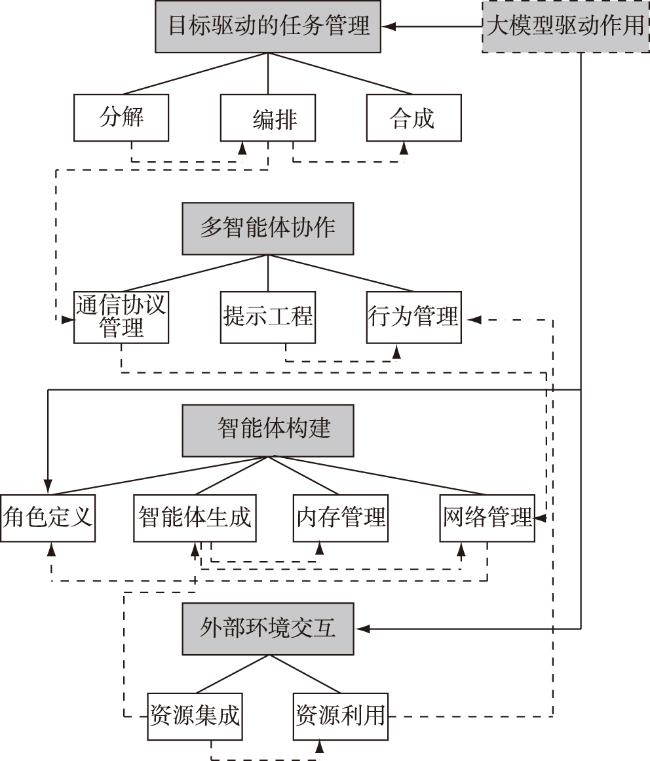
首先,目标驱动的任务管理模式的工作流程包括分解、编排和合成三个核心功能。在目标分解功能,系统能够将复杂任务分解为可管理的任务和子任务;通过解决子任务之间的相互关系,从而产生具有优先级排序的任务列表。在任务编排功能,系统获取分解后的任务列表,组织合适的智能体网络进行任务的分配和委派,并指定具有特定功能的智能体进行子任务的处理。在结果合成功能,系统对智能体网络反馈的处理结果进行评估和合并,最终呈现统一的处理结果,并传输至用户界面进行结果反馈。
其次,智能体构建模式的工作流程包括智能体生成、角色定义、内存使用和网络管理4个核心功能。在智能体生成功能,系统根据用户或架构师的预定义规则或外部资源条件,生成多个处理指定任务的智能体,并对多智能体网络进行任务分配。在角色定义功能,系统根据子任务编排结果,对智能体的功能角色和执行功能等属性进行定义,使得智能体能够自动执行分配任务。在内存使用功能,系统根据多智能体运行产生的已有记忆节点总量分配相应静态和动态内存,并进行分配内存的实时管理。在网络管理功能,系统根据任务编排结果,对多智能体网络的运行状态进行实时监督和任务分配的实时调整。
再次,多智能体协作模式的工作流程包括通信协议管理、提示工程、行动管理3个核心功能。在通信协议管理功能,系统根据外部资源条件和硬件系统配置确定多智能体之间交互的通信协议,并对通信进程进行实时监督管理。在提示工程功能,系统通过提示指令的开发和优化,与大模型进行交互,以引导大模型产生所期望的结果。在行动管理功能,系统对多智能体之间的交互和智能体与大模型的交互行为进行实时监督和进程管理。
最后,外部环境交互模式的工作流程包括资源集成和资源领域两个核心功能。在资源集成功能,系统获取外部环境提供的工具、数据集或基础模型资源,并集成到多智能体交互层。在资源利用功能,系统根据任务编排和分配结果,从外部环境获取任务处理所需的特定资源,并通过智能体网络进行资源处理和结果生成。
2 基于大模型驱动的多智能体系统的多维评估体系
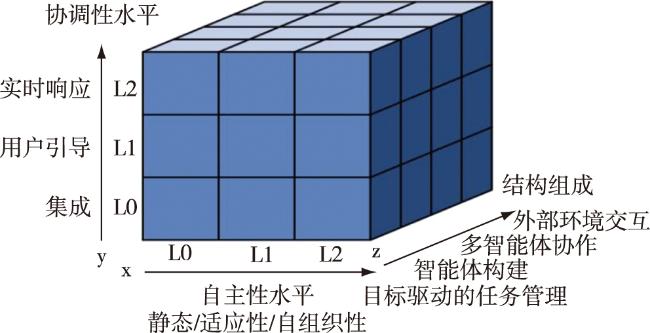
本文通过建立多维评估体系,分析大模型驱动的多智能体系统架构中自主性和一致性之间的相互作用,并对大模型驱动的多智能体系统进行全面的评估。评估方法主要包括3个关键维度,即自主性级别、一致性级别以及架构组成模式。多维评估体系的简化表示如图3 所示,其中x轴表示自主性级别,y轴表示一致性级别,z轴表示系统架构的4个组成模式。本文通过将大模型驱动的多智能体系统的特征置于此评估结构,实现对多智能体系统的性能评估。
2.1 自主性评估
自主性程度是指人工智能系统能够独立于用户定义的规则和机制做出决策和行动的程度。在大模型驱动的多智能体系统中,自主性程度表示系统以自组织方式解决用户指定的目标或任务,适应环境和重新校准给定情况的复杂性能力。从图4 所示的用户、规则机制和大模型驱动的多智能体之间的相互作用中可以看出,低自主性的系统严重依赖于预先设置的定义规则和框架,难以独立解决用户指定的目标或意图,而高自主性的系统不依赖于定制的规则框架,能够直接处理用户给定任务需求。

在大模型驱动的多智能体系统中,自主性水平表示在多智能体独立于预定义和自动化机制的情况下做出有关系统操作的决策的程度,主要可划分为静态自主性、自适应自主性和自组织自主性。L0表示静态自主性级别,对应系统严重依赖于架构师嵌入的规则、条件和机制,且智能体无权在运行时修改规则,仅能够有效执行分配的任务;L1表示自适应自主性级别,对应系统能够在架构师建立的结构和程序指南内调整其行为,智能体能够根据给定应用场景需求,在提供的框架(例如灵活的基础设施和协议)内调整系统操作;L2表示自组织自主性级别,对应系统智能体成为主要参与者,能够自我组织、主动学习并根据环境线索和经验实时动态调整其操作。
2.2 一致性评估
一致性程度是指对与用户指定的目标或复杂任务相关的偏好、策略、约束和边界等条件的详细校准,衡量系统用户影响或调整系统行为的程度。低一致性的系统设置了广泛的行为边界,而不关注特定的用户偏好;高一致性的系统适应性更强,并以用户指定的任务为中心,用户可以灵活在其活动操作期间设置偏好,系统的动态范围确保生成结果更贴合用户目标。
在大模型驱动的多智能体系统中,一致性水平衡量了系统用户影响或调整系统行为的程度,主要可划分为集成一致、用户引导一致和实时响应式一致。L0表示集成一致级别,对应系统中的一致机制是静态的和规则驱动的,用户无法更改;L1表示用户引导一致级别,对应系统提供了一定程度的自定义,允许用户在系统开始运行之前设置或调整特定的一致参数(例如条件、规则或边界);L2表示实时响应式一致级别,对应系统可以在关键时刻或决策点主动征求用户反馈和用户决策,使得用户和系统之间能够持续反馈,从而实现高水平的协作。
2.3 自主性与一致性综合评估体系
通过结合自主性和一致性两个维度,图5 展示了大模型驱动的多智能体系统中不同层次的自主性和一致性之间的相互作用。y轴代表一致性级别,箭头起始为用户角色为被动的集成一致级别(L0)指向到需要主动参与的实时响应一致级别(L2);x轴代表自主性级别,箭头起始为静态自主性级别(L0)发展到自组织自主性级别(L2)。
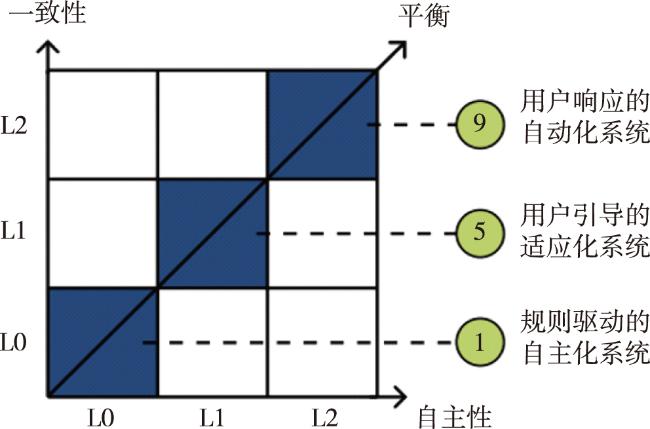
可知,不同层次的自主性和一致性之间的相互作用能够形成9种评估标准,如表1 所示。当系统的自主性水平为静态自主性级别(L0),一致性水平为集成一致级别(L0)时;或者系统的自主性水平为自适应自主性级别(L1),一致性水平为用户引导一致级别(L1)时;或者系统的自主性水平为自组织自主性级别(L2),一致性水平为实时响应一致级别(L2)时,系统的自主性与一致性能够达到平衡状态,分别对应为规则驱动的自动化系统、用户引导适应系统和用户响应系统。此外,若系统的自主性水平高于一致性水平,系统可能
表1 大模型驱动的多智能体系统的自主性水平与一致性水平的相互作用结果Tab.1 The interaction results of autonomy and consistency level in multi-agent systems driven by large language models |
| 自主性/一致性级别 | 静态自主性级别 | 自适应自主性级别 | 自组织自主性级别 |
|---|---|---|---|
| 集成一致性级别 | 规则驱动的自动化系统 | 预配置自适应系统 | 有限自治系统 |
| 用户引导一致性级别 | 用户引导的自动化系统 | 用户引导的自适应系统 | 用户引导的自治系统 |
| 实时响应一致性级别 | 用户监督的自动化系统 | 用户协作的自适应系统 | 用户响应的自治系统 |
出现处理结果与用户预期意图偏离较大的问题;若系统的一致性水平高于自主性水平,系统可能出现对复杂任务的处理能力低下、过度依赖用户预制规则的问题。因此,大模型驱动的多智能体系统通过建立自主性和一致性水平之间的平衡,能够实现多智能体的高效协作。将自主性与一致性的综合评估结果应用于大模型驱动的多智能体架构的4个组成模式中,形成36个不同的相互作用结果,如表2 所示。
表2 大模型驱动的多智能体系统在不同架构组成模式下的自主性水平与一致性水平的相互作用结果Tab.2 The interaction results of autonomy and consistency level of multi-agent systems driven by large language models with different architectural composition mode |
| 自主性/一致性级别 | 目标驱动的任务管理 | 智能体构建 | 多智能体协作 | 外部环境交互 |
|---|---|---|---|---|
| 规则驱动的自动化系统 (L0,L0) | 规则驱动的 任务管理 | 规则驱动的 智能体生成 | 规则驱动的协作协议 | 规则驱动的环境 资源交互 |
| 用户引导的自动化系统 (L0,L1) | 用户引导的任务管理 | 用户引导的 智能体生成 | 用户引导的协作协议 | 用户引导的 资源整合利用 |
| 用户监督的自动化系统 (L0,L2) | 运行期间调整任务管理 | 运行期间调整 智能体构建 | 运行期间调整协作方式 | 运行期间调整 资源利用率 |
| 预配置自适应系统 (L1,L0) | 具有预定义选项的 自适应任务管理 | 自适应智能 体组合 | 自适应协作协议 | 预集成与 自适应环境资源 |
| 用户引导的自适应系统 (L1,L2) | 用户调整的自适应 任务管理 | 用户调整的自适应 智能体构建 | 用户调整的 自适应协作 | 用户调整的自适应 环境整合和利用 |
| 用户协作的自适应系统 (L1,L2) | 运行时调整自 适应任务管理 | 运行时调整自适应 智能体构建 | 运行时调整自 适应协作 | 运行时调整自适应 环境整合和利用 |
| 有限自治系统 (L2,L0) | 基于预设需求的 自组织任务管理 | 自组织智 能体构建 | 基于预设需求的 合作策略 | 自主选择资源来源 |
| 用户引导的自治系统 (L2,L1) | 用户引导的自 组织任务管理 | 用户引导的自 组织智能体 | 用户引导的 自组织协作 | 用户引导的自组织 选择资源来源 |
| 用户响应的自治系统 (L2,L2) | 运行时自组织 调整任务管理 | 运行时自组织调整 智能体构建 | 运行时自组织 调整协作 | 运行时自组织 调整资源来源 |
在此基础上,对系统性能的综合评估结果可包括3种形式:第一种是系统各功能之间相互独立,即不存在相互影响和耦合关系,对应的每个核心功能的评估结果不受其他功能的评估结果影响,这种完全独立系统的所有不重复的评估结果总数为T1;第二种是系统的各功能仅受到相同架构组成模式下的其他核心功能影响,在不同架构组成模式下的两个运行功能均相互独立,这种模式耦合的系统的所有不重复的评估结果总数为T2;第三种是系统的所有运行功能之间均能够互相影响或存在耦合作用,不存在相互独立的两个核心功能,这种完全耦合的系统的所有不重复的评估结果总数为T3。这三类系统分别对应的评估结果总数能够间接反映系统的复杂程度,关系公式如下:
$T_{1}=T_{0} S_{0}$
T2=
T3= =
根据上式,可得T1=108,T2=2×93+92+94=8 100,T3=912≈282×109。因此,在系统的所有运行功能下,完全独立的系统通过多维评估体系能够生成108个不同的评估结果;完全耦合的系统需要考虑各功能的所有可能组合,能够得出总共912个组合评估结果,相当于2 820亿个可用于配置大模型驱动的多智能体架构的组合。该数据体现了基于大模型多智能体系统的多维评估方法能够有效应用于具备不同特征功能的复杂系统的性能综合评估。
3 实验
首先,AutoGPT是一种基于GPT-4的自动化文本生成模型,能够根据用户设定角色,自动拆解任务并协作完成。在任务分解过程中,AutoGPT系统能够对用户定义目标进行自主分解获取任务,确定任务的优先级,对应分解自主性为L2;在编排过程中,该系统包含3个不同的任务管理智能体:执行智能体、任务创建智能体和任务优先级排序智能体,但所有任务都由单一的执行智能体按优先级顺序执行,对应编排自主性为L0;在合成过程中,系统完成每项任务后会评估中间结果并进行自我批评,最终处理结果是所有智能体处理结果的集合,并辅以简洁的摘要,对应合成自主性为L1;在通信协议管理中,系统3个代理之间的通信遵循预定义的通信协议,无须进行通信协议管理,对应通信协议管理自主性为L0;在提示工程中,系统的提示工程能够基于模板进行生成,对应提示工程自主性为L1;在行动管理中,系统能够实现对智能体执行的操作进行自组织管理,对应行动管理自主性为L2;在智能体生成中,该系统中的智能体是预先配置的,并且只能实例化一次,对应智能体生成自主性为L0;在角色定义中,系统的执行智能体的角色是自适应的,对应角色定义自主性为L1;在内存管理中,系统的内存使用和网络管理都遵循预定义的规则,对应内存管理和网络管理功能的自主性均为L0;在资源集成中,系统配备了一套预定义的外部环境资源,无须集成其他外部环境资源,对应资源集成的自主性为L0;在资源利用中,系统将这些资源根据场景的需要以自组织的方式使用,在资源利用功能表现出L2的自主性。此外,系统在各个方面仅提供了低级别的用户交互,除了目标传输之外,进一步的用户交互仅可通过授权后续执行步骤才能使用,且在大部分情况下系统通过连续模式跳过该授权步骤,使用户无法进一步干预,因此系统在所有功能的一致性级别均为L0。
HuggingGPT是一个基于ChatGPT的大模型协作系统,它通过语言接口连接和管理平台上的智能体模型,解决多模态和复杂的人工智能任务。HuggingGPT系统采用不同的多智能体协作策略,将大模型驱动的智能体作为自主控制器,结合各种多模态智能体模型来解决复杂任务。系统集成了HUGGING FACE平台,该平台提供了大量可供使用的基础模型。在任务分解过程中,系统采用的由大模型驱动的单一中央代理适用于解决给定目标,能够自主地将目标或复杂任务分解为可管理的任务,对应分解功能自主性水平为L2;在其他过程中,系统通过提示选择、组合和应用适当的模型,使得集成、资源利用、提示工程、行动管理、智能体生成和角色定义功能的自主性级别达到L2;此外,系统可适应给定的任务,包括由预定义流程组成的通信协议管理、高级流程框架规划、模型选择、任务执行和响应生成,对应编排、通信协议管理、内存管理功能的自主性级别为L1;系统的网络管理遵循预定义的规则,对应网络管理功能的自主性级别为L0。尽管HuggingGPT在大模式功能的自主性水平较高,但它并没有给予用户在任何功能下的定制或监督选择,导致系统的一致性级别均为L0。
CAMEL系统框架是目前首个基于大模型的多智能体框架。CAMEL系统采用由大模型驱动的通信智能体之间自主合作以完成复杂任务的方式,自主处理用户给定的提示目标。在任务分解过程中,系统通过专用任务指定智能体将目标分解为可管理任务列表,对应分解功能的自主性为L2;在其他过程中,系统通过循环对话模式协同的智能体处理任务,对应编排、通信协议管理和网络管理中的自主性为L0;用户可以选择预定义智能体原型的特定角色,通过智能体的定义和相互关系进行调控,对应角色定义、网络管理和智能体生成功能的一致性均为L1;系统在提示工程和行动管理中都实现了较高的自主性。
3.1 系统自主性和一致性水平评估
表3 大模型驱动的多智能体系统在不同核心功能下的自主性水平的评估结果Tab.3 Evaluation results of autonomy level of multi-agent systems driven by large language models |
| 大模型多智 能体系统 | 分解 | 编排 | 合成 | 通信 | 提示 | 行动 | 智能 体 | 角色 | 内存 | 网络 | 集成 | 利用 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Auto-GPT | 2 | 0 | 1 | 0 | 1 | 2 | 0 | 1 | 0 | 0 | 0 | 2 |
| BabyAGI | 2 | 0 | 1 | 0 | 1 | 2 | 0 | 1 | 0 | 0 | 0 | 2 |
| SuperAGI | 2 | 1 | 1 | 0 | 1 | 2 | 1 | 2 | 0 | 0 | 0 | 2 |
| HuggingGPT | 2 | 1 | 2 | 0 | 2 | 2 | 2 | 2 | 1 | 0 | 2 | 2 |
| MetaGPT | 2 | 0 | 2 | 1 | 1 | 2 | 0 | 0 | 0 | 1 | 0 | 2 |
| CAMEL | 2 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| AgentGPT | 2 | 1 | 1 | 0 | 1 | 2 | 1 | 2 | 0 | 0 | 0 | 2 |
表4 大模型驱动的多智能体系统在不同核心功能下的一致性水平的评估结果Tab.4 Evaluation results of consistency level of multi-agent systems driven by large language models |
| 大模型多智 能体系统 | 分解 | 编排 | 合成 | 通信 | 提示 | 行动 | 智能 体 | 角色 | 内存 | 网络 | 集成 | 利用 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Auto-GPT | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BabyAGI | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| SuperAGI | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 |
| HuggingGPT | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| MetaGPT | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CAMEL | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| AgentGPT | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
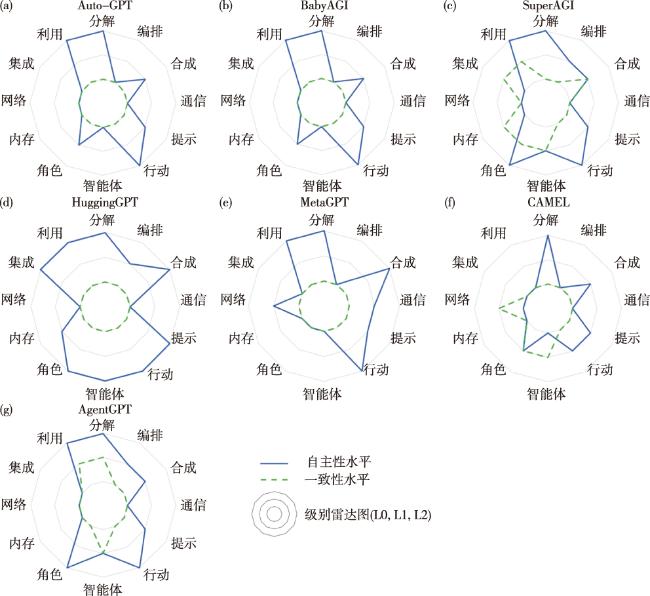
在自主性方面,较多系统在核心功能下的自主性水平表现出相同的变化规律,故可根据评估结果统计分析所有系统在不同运行功能下的自主性水平分布。首先,具有高自主性表现的运行功能的基本特征为具有自组织、自主决策的大模型驱动智能体参与运行,主要包括目标分解、行动管理、外部环境交互功能,对应自主性级别基本能够达到L2;其次,系统在具有中等自主性水平的运行功能采用半自主策略,即通过由大模型驱动的多智能体适应的预定义机制进行任务处理,主要包括合成、提示工程功能;再次,系统在低自主性水平的运行功能采用基于规则的机制和自动化的确定性策略,主要包括编排、通信协议管理、内存管理、网络管理和资源集成功能。最后,系统在智能体生成和角色定义功能的自主性水平表现出多样性,因为不同系统的多智能体协作采用不同的策略。
在一致性方面,大多数系统的主要策略是在所有评估方面保持较低水平的一致性,并且在已经集成到系统架构中的一致性技术中,几乎没有可供用户调整的选项。此外,系统通过具有预定义和自动化机制的高自主性功能来补偿对应功能在一致性方面的不足。但是,少数大模型系统能够在特定功能提供中等水平的一致性,对应功能包括智能体生成、角色定义和资源利用。此外,数据显示所有受检系统都缺乏实时响应的一致性选项,少数大模型系统为用户提供了可用的监控功能,提升执行智能体在任务反思和规划期间的推理能力和决策的透明度。
此外,研究将所选的7个系统按不同功能下的性能表现分为3个不同的系统组,包括通用系统组、中央控制器系统组和角色智能体系统组。需要注意的是,本文采用的评估系统组没有涵盖大模型驱动的多智能体系统的全部范围,如需全面了解现有系统评估类别可参考已有研究[19-20]。下面将讨论3类大模型驱动的多智能体系统组对应的关键特征。首先,通用系统组包括AUTO-GPT、 BABYAGI、 SUPERAGI和AGENTGPT系统,这些系统因为通过任务执行智能体的方式进行多智能体交互,对应通信协议管理和网络管理的自主性水平较低,行动管理和资源利用的自主性级别达到L2,因此这类系统具有较强的适应能力,能够适用于具有广泛功能的任务;其次,中央控制器系统组包括HUGGINGGPT系统,系统特点为单个由大模型驱动的中央控制智能体被赋予了最高级别的自主权,且没有以用户为中心的一致性选项,对应一致性水平均为L0,自主性水平基本接近较高级别,这类系统处理复杂任务的能力较强,但用户交互性较差,对应HuggingGPT的自主性水平明显高于其他选定系统;最后,角色智能体系统组包括METAGPT和CAMEL系统,特点为采用多个专用角色智能体之间的相互作用或模拟,对应编排和通信协议管理的性能较差,适用于特点应用领域或解决多视角协作的任务。
3.2 系统发展方向分析

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
图8 大模型驱动的多智能体系统在不同功能的自主性和一致性水平的分布结果Fig.8 Distribution of autonomy and consistency level of different functions of multi-agent systems driven by large language models |
表5 大模型驱动的多智能体系统在不同核心功能下的自主性和一致性水平的评估结果比较Tab.5 Comparison of the evaluation results of autonomy and consistency level of multi-agent systems driven by large language models |
| 核心功能 | 静态自主 性级别总数 | 自适应自主 性级别总数 | 自组织自主 性级别总数 | 集成一致 性级别总数 | 用户引导一致 性级别总数 | 实时响应一致 性级别总数 |
|---|---|---|---|---|---|---|
| 分解 | 0 | 0 | 7 | 6 | 1 | 0 |
| 编排 | 4 | 3 | 0 | 7 | 0 | 0 |
| 合成 | 0 | 5 | 2 | 6 | 1 | 0 |
| 通信协议管理 | 6 | 1 | 0 | 7 | 0 | 0 |
| 提示工程 | 0 | 6 | 1 | 7 | 0 | 0 |
| 行动管理 | 0 | 1 | 6 | 7 | 0 | 0 |
| 智能体生成 | 4 | 2 | 1 | 4 | 3 | 0 |
| 角色定义 | 1 | 3 | 3 | 5 | 2 | 0 |
| 内存管理 | 6 | 1 | 0 | 6 | 1 | 0 |
| 网络管理 | 6 | 1 | 0 | 6 | 1 | 0 |
| 资源集成 | 6 | 0 | 1 | 6 | 1 | 0 |
| 资源利用 | 1 | 0 | 6 | 5 | 2 | 0 |
在自主性方面,选定的系统在编排、通信协议管理、内存管理、网络管理和资源集成等核心功能的自主性水平较低,大模型系统自主性级别仅为L0;在分解、行动管理和资源利用功能的自主性水平较高,大模型系统的自主性级别达到L2;在合成、提示工程、智能体生成和角色定义功能的自主性处于中等水平,大模型系统的自主性级别为L1。目前,因为智能体之间的协作主要依靠预定义的任务执行智能体之间的受限通信协议,或具有预定义执行链的顺序或多周期过程,研究人员可通过使用大模型驱动的智能体来管理,或者调整智能体网络的生成及其协作模式,从而提升系统的编排、通信协议管理、内存管理和网络管理功能的自主性水平;此外,研究人员可通过配置智能体可直接获取的外部接口或提供可集成的资源环境,提升系统的资源集成功能的自主性水平。
在一致性方面,选定的系统在12个核心功能的一致性水平均较低,大模型系统的一致性级别仅为L0,远低于系统的自主性水平。因此,用户能够访问和影响系统内部工作的选项非常有限,并且代理的内部组成和协作对用户来说基本是不透明的,这降低了系统操作的透明度,影响系统决策的可信度。虽然某些系统提供了用户反馈和规划的渠道,但大模型系统的内部机制的定制选择不提供给用户。因此,系统需要在代理生成和角色定义功能加入用户调整选项,并在通信协议管理、任务编排或结果综合功能加入用户可修改的内容,通过增强实时监控,提升系统在各功能的一致性水平。
4 结束语
本文提出了一种基于大模型驱动的多智能体系统的多维评估体系,通过层次结构矩阵在4个架构组成模式下的映射,产生的复杂评估系统能够对现有系统架构中自主性和一致性之间的相互作用进行评估。该评估法通过目标驱动的任务管理、多智能体协作、智能体构建和外部环境交互组成模式对应的12个不同的核心功能,能够对大模型驱动的多智能体系统中的架构复杂性进行细致的分解。本文对已有的7个典型大模型驱动的多智能体系统进行性能评估,得到3组具有不同性能特征的多智能体系统组,并对系统现有性能和发展前景进行综合分析,验证了多维评估体系在实际系统评估领域中的有效性。
目前,本文通过7个大模型多智能体系统的实验结果验证方法的有效性,但选取的验证系统尚未全面覆盖不同规模和复杂程度的多智能体系统,可能影响实验结果的广泛性和普适性。在未来发展中,本文所提的方法将在更大规模、更复杂的大模型多智能体系统上进行验证,进一步提升研究的完备性和应用价值。