 PDF(1587 KB)
PDF(1587 KB)

Virtual commander’s operational decision-making model based on thinking simulation
JIA Chenxing, MING Yuewei, GE Chenglong
PDF(1587 KB)
 中国指挥与控制学会会刊
军事装备类重点期刊
中国指挥与控制学会会刊
军事装备类重点期刊
Virtual commander’s operational decision-making model based on thinking simulation
Focusing on the urgent need of joint operational plan simulation experimentation, aiming at the lack of intelligent decision-making ability of command entity in the current joint operations simulation systems, and the difficulty of popularizing the simulation experimentation pattern of man-not-in-loop, this paper researches a joint campaign level simulation intelligence which named virtual commander in the simulation loop to simulate the thinking and behavior of human commander’s operation decision-making. This paper puts forward the definition and orientation of virtual commander’s operational decision-making, constructs a framework of virtual commander’s operational decision-making model, and designs the virtual commander’s operational decision-making thinking model, behavior model and simulation model based on the theory of natural decision-making, which provides a feasible solution to the bottleneck problem of simulation experimentation pattern of Man-Not-In-Loop.
virtual commander; decision-making modeling; natural decision-making theory; model framework; joint operational plan simulation experimentation {{custom_keyword}};
| [1] |
李梦汶. 联合作战仿真实验的几个基本问题[J]. 军事运筹与系统工程, 2008, 22(1): 25-29.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [2] |
胡红云, 郑世明. 联合作战方案仿真推演控制研究[J]. 军事运筹与系统工程, 2016, 30(1): 76-80.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [3] |
刘兆鹏, 柳少军, 司光亚, 等. 面向推演分析的联合作战方案概念建模研究[J]. 系统仿真学报, 2018, 30(12): 4 563-4 573.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [4] |
刘海洋, 唐宇波, 胡晓峰, 等. 基于兵棋推演的联合作战方案评估框架研究[J]. 系统仿真学报, 2018, 30(11): 4 115-4 122, 4 131.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [5] |
秦园丽, 张训立, 高桂清, 等. 基于兵棋推演系统的作战方案评估方法研究[J]. 兵器装备工程学报, 2019, 40(6): 92-95.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [6] |
李云龙, 张艳伟, 王增臣. 联合作战方案推演评估技术框架[J]. 指挥信息系统与技术, 2020, 11(4): 78-83.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [7] |
温睿. 作战方案计划推演评估[M]. 北京: 兵器工业出版社, 2019.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [8] |
彭勇. 作战方案仿真实验自动指挥决策问题研究[J]. 军事运筹与系统工程, 2017, 31(3): 47-50.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [9] |
李策, 杨博. 基于仿真的陆军合同战斗方案实验评估研究[J]. 计算机仿真, 2020, 37(9): 31-35,76.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [10] |
李策, 申天良, 彭勇, 等. 陆军合同战斗方案仿真实验自动控制研究[J]. 指挥控制与仿真, 2018, 40(1): 86-92.
针对仿真实验自动控制面临的困难问题,运用作战方案筹划中决策点概念,提出了实现方案仿真自动控制的思路和方法。首先,确定了决策点设计原则,构建了通用性决策点体系,并给出了决策点的格式化形式;其次,探讨了满足自动控制仿真所需要的战斗方案要素构成以及指挥信息元素的表格化表达方式;再次,建立了由数据化的作战方案、自动控制规则、仿真环境和仿真模型等组分等构成的仿真自动控制框架;最后,通过一个简化的陆军摩步旅进攻战斗想定验证了其可行性。
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [11] |
贺筱媛, 郭圣明, 吴琳, 等. 面向智能化兵棋的认知行为建模方法研究[J]. 系统仿真学报, 2021, 33(9):2037-2 047.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [12] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
PDF(1587 KB)
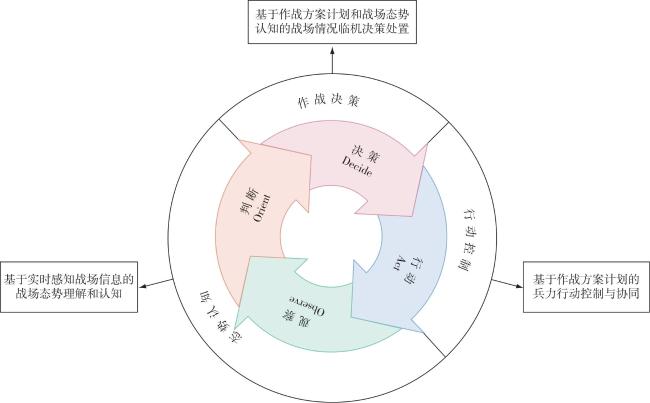
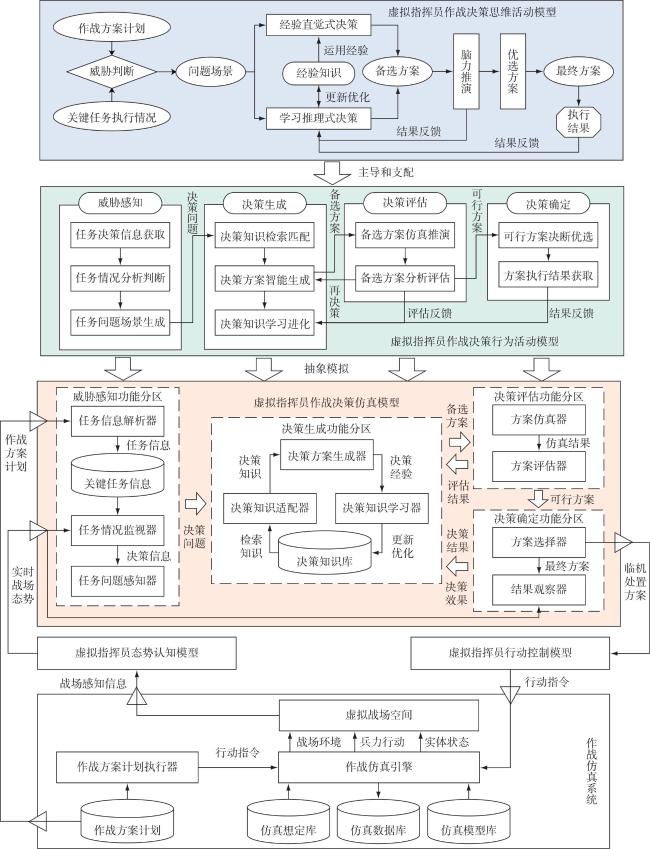
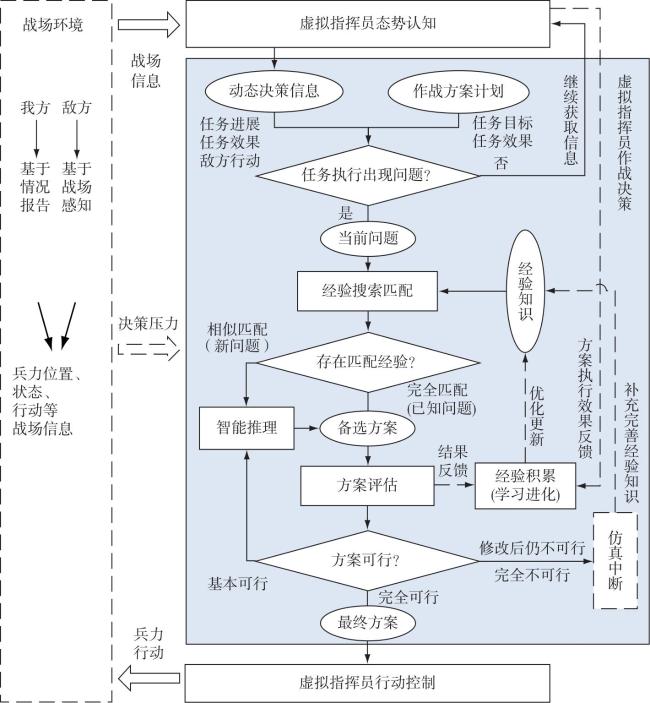
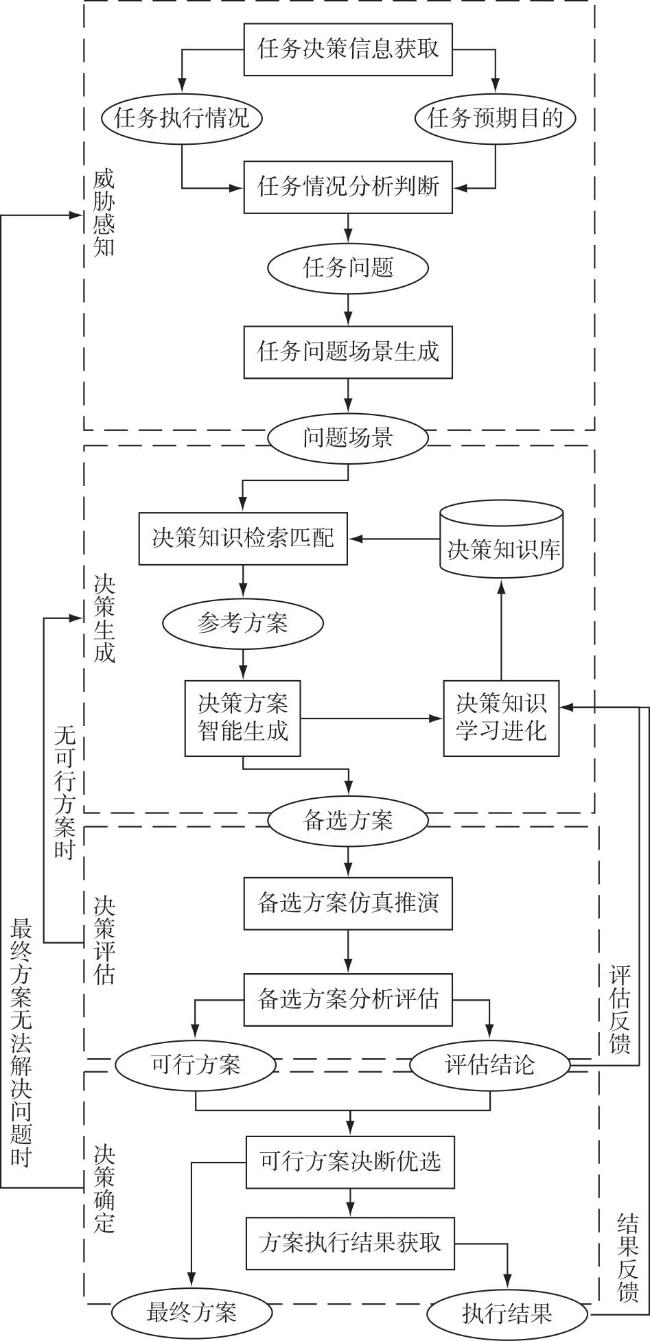
 Fig.1 Three core capabilities of virtual commander based on OODA loopFig.2 System framework of virtual commander’s operational decision-making modelFig.3 Concept model of virtual commander’s operational decision-making thinkingFig.4 Concept model of virtual commander’s operational decision-making behavior
Fig.1 Three core capabilities of virtual commander based on OODA loopFig.2 System framework of virtual commander’s operational decision-making modelFig.3 Concept model of virtual commander’s operational decision-making thinkingFig.4 Concept model of virtual commander’s operational decision-making behavior/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}